通过分析C++ STL容器,理解基础数据结构。
一、动态数组 vector
数组:相同类型、连续内存、顺序存储。因此能基于下标,实现对数组元素O(1)的随机访问:数组的开始地址 + index * 元素大小。
静态数组需要提前指定数组大小,如果实际使用超过了数组大小,需要手动实现申请一片更大内存,将原来数组的内容拷贝到新内存,并释放原本内存的操作。动态数组把这些细节封装起来,无需用户关注扩容的操作。
vector定义和扩容实现
1
2
3
4
5
6
7
8
9
10
| template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class vector : protected _Vector_base<_Tp, _Alloc>
{
...
protected:
_Tp* _M_start; //表示目前使用空间的头
_Tp* _M_finish; //表示目前使用空间的尾
_Tp* _M_end_of_storage; //表示目前可用空间的尾
...
};
|
存了3个指针,分别表示数组的开始、结束、可用空间的结束。据此可以计算出size和capacity。
当capacity不足时,会触发扩容,测试扩容:
1
2
3
4
5
6
7
8
9
10
| #include <vector>
#include <iostream>
int main() {
std::vector<int> v;
for (int i = 0; i < 20; i++) {
std::cout << "size: " << v.size() << " capacity " << v.capacity() << std::endl;
v.push_back(i);
}
return 0;
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| size: 0 capacity 0
size: 1 capacity 1
size: 2 capacity 2
size: 3 capacity 4
size: 4 capacity 4
size: 5 capacity 8
size: 6 capacity 8
size: 7 capacity 8
size: 8 capacity 8
size: 9 capacity 16
size: 10 capacity 16
size: 11 capacity 16
size: 12 capacity 16
size: 13 capacity 16
size: 14 capacity 16
size: 15 capacity 16
size: 16 capacity 16
size: 17 capacity 32
size: 18 capacity 32
size: 19 capacity 32
|
观察到当size > capacity时会触发扩容。并且capacity按2的指数倍增长。
vector扩容逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| void push_back(const _Tp& __x) {//在最尾端插入元素
if (_M_finish != _M_end_of_storage) {//若有可用的内存空间
construct(_M_finish, __x);//构造对象
++_M_finish;
}
else//若没有可用的内存空间,调用以下函数,把x插入到指定位置
_M_insert_aux(end(), __x);
}
template <class _Tp, class _Alloc>
void
vector<_Tp, _Alloc>::_M_insert_aux(iterator __position, const _Tp& __x)
{
if (_M_finish != _M_end_of_storage) {
construct(_M_finish, *(_M_finish - 1));
++_M_finish;
_Tp __x_copy = __x;
copy_backward(__position, _M_finish - 2, _M_finish - 1);
*__position = __x_copy;
}
else {
const size_type __old_size = size();
const size_type __len = __old_size != 0 ? 2 * __old_size : 1;
iterator __new_start = _M_allocate(__len);
iterator __new_finish = __new_start;
__STL_TRY {
__new_finish = uninitialized_copy(_M_start, __position, __new_start);
construct(__new_finish, __x);
++__new_finish;
__new_finish = uninitialized_copy(__position, _M_finish, __new_finish);
}
__STL_UNWIND((destroy(__new_start,__new_finish),
_M_deallocate(__new_start,__len)));
destroy(begin(), end());
_M_deallocate(_M_start, _M_end_of_storage - _M_start);
_M_start = __new_start;
_M_finish = __new_finish;
_M_end_of_storage = __new_start + __len;
}
}
|
扩容在_M_insert_aux中实现:
- 确保当前size等于capacity
- 申请当前size两倍的内存空间
- 深拷贝
- 释放原有内存空间
- 更新vector中的指针
思考:为什么会设计成倍增?
若每次扩容固定增加 k 个空间,连续插入 n 个元素的总拷贝次数为:
k + 2k + 3k + ... + n ≈ n²/(2k) = O(n²),
均摊到每次 push_back 是 O(n),性能随规模急剧恶化。
容量按 1, 2, 4, 8, …, n 增长,总拷贝次数:
1 + 2 + 4 + ... + n ≈ 2n = O(n),
均摊到每次 push_back 是 O(1)。这就是「push_back 均摊 O(1)」的来源。
所以,vector扩容设计成倍增,是为了保证push_back的均摊复杂度为O(1)。不同的编译器扩容因子可能不同,gcc和clang默认是2,msvc默认是1.5。选2可以做到时间最优,但是为什么有的编译器选择1.5?
- 1.5的最差空间利用率更高
- 考虑到内存复用的问题,假设扩容因子为2,已分配块大小依次是 1, 2, 4, 8, 16…:1+2+4+…+2^(k-1)=2^k-1<2^k,前面所有已释放内存加起来,永远不够装下下一次扩容的大小。如果使用对齐内存池,会导致数组扩容只能往堆的高地址不断延伸,对内存分配器不友好。
思考:为什么pop不会触发缩容?
扩容是必要性问题,而缩容不是必须的。有可能用户就是需要保持原本的容量,所以是否缩容的选择应该交给使用者。这是STL的设计哲学:零开销抽象,把策略留给用户。
- 对象池 / 复用:vector 被反复清空再填充,保留 capacity 反而避免了反复申请释放,性能更好。
- 容量稳定抖动:size 在某个区间波动,释放只会带来无用拷贝。
- 明确知道不再增长:用户可以主动调用
shrink_to_fit()。
同时C++标准层面的硬约束:pop_back、clear、erase 在标准里都被视为不应失败的操作。如果执行缩容,需要重新申请内存,可能会分配失败,就不符合规范(影响整个RAII析构链)。
二、双向链表 list
链表:顺序结构,使用指针关联节点地址,无需连续存储,一般来说比数组的内存使用率更高(无需提前分配)。链表更适用于删除、插入、遍历操作频繁的场景,而不适用于随机访问索引频繁的场景,如内存池、LRU。
链表主要包括单链表、双向链表、循环链表。STL中的list则是循环双向链表: 实现双向迭代器,支持std::reverse、list::reverse()、list::sort()等算法的实现。
list定义和实现
链表节点的定义:
1
2
3
4
5
6
| template <class T>
struct __list_node {
__list_node<T>* next; // 前驱节点指针
__list_node<T>* prev; // 后继节点指针
T data; //存储数据
};
|
list定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| template<typename T>
class list{
protected:
typedef __list_node<T> list_node; // 显示定义list_node类型
typedef allocator<list_node> nodeAllocator; // 定义allocator类型
public:
typedef T value_type;
typedef T& reference;
typedef value_type* pointer;
typedef list_node* link_type;
typedef const value_type* const_pointer;
typedef size_t size_type;
public:
typedef __list_iterator<value_type> iterator; // 迭代器类型重写
private:
link_type node; // dummy节点
// ......
}
|
每个list都有一个虚拟节点,用于标记整个循环链表的首位连接处:
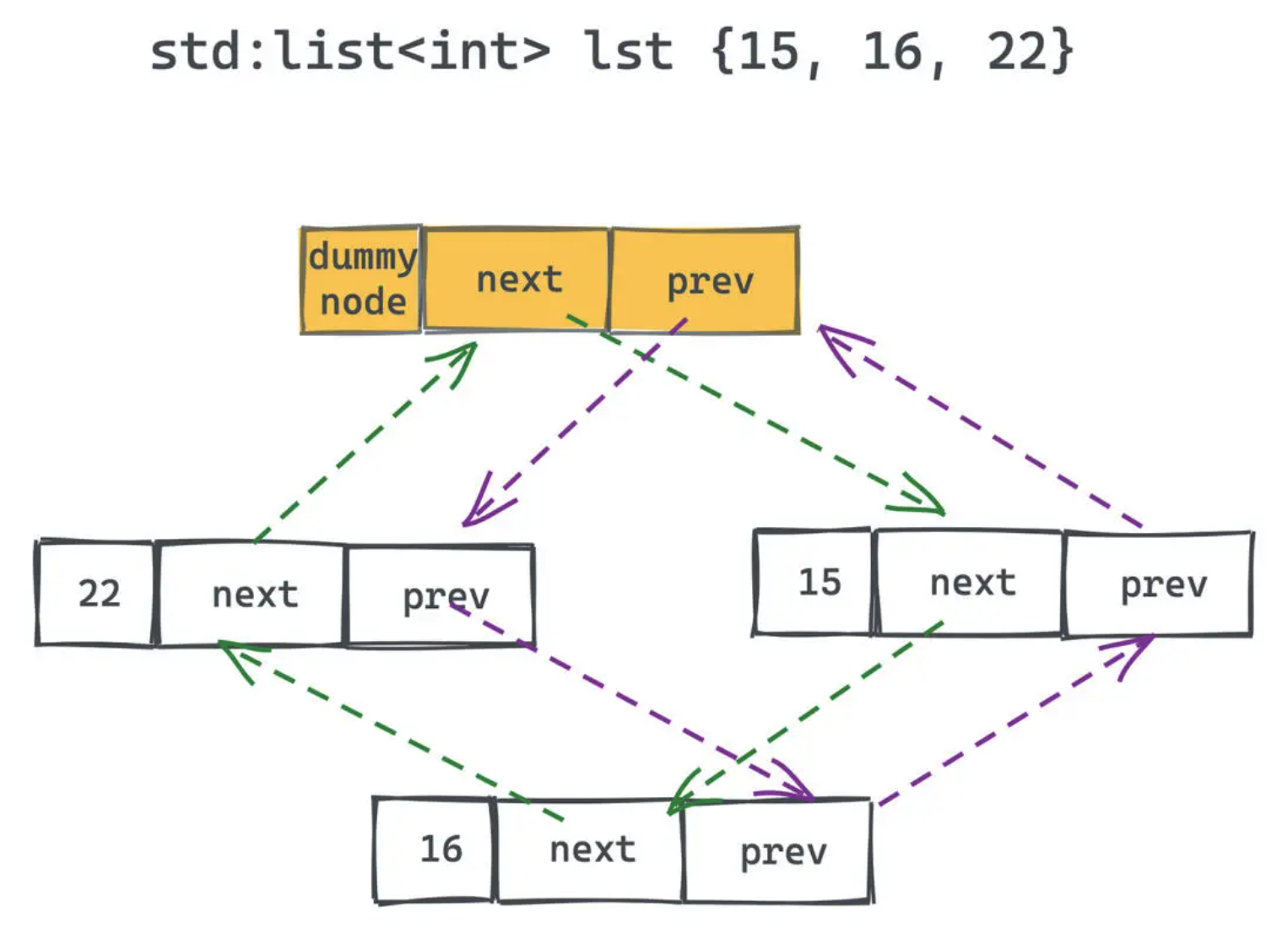
dummy节点的引入是为了统一end语义:end指向的都是无效值。因此遍历list写法:
1
2
3
| for (std::list<int>::iterator it=mylist.begin(); it != mylist.end(); ++it) {
std::cout << ' ' << *it;
}
|
insert和erase实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| // 在position之前插入节点
iterator insert(iterator position, const T& x) {
lik_type tmp = create_node(x); // 创建一个临时节点
tmp->next = position.node; // 将该节点的后继指针指向当前位置的节点
tmp->prev = position.node->prev; // 将该节点的前驱指针指向当前位置的前驱节点
(link_type(position.node->prev))->next = tmp; // 将前驱节点本来指向当前节点的后继指针改为指向该临时节点
position.node->prev = tmp; // 同样,当前位置的前驱指针也要修改为指向该临时节点
return tmp;
}
// 删除position的节点
iterator erase(iterator position) {
link_type next_node = link_type(position.node->next);
link_type prev_node = link_type(position.node->prev);
prev_node->next = next_node;
next_node->prev = prev_node;
destroy_node(position.node);
return iterator(next_node);
}
|
据此可以实现:
push_back(x): insert(end(), x)push_front(x): insert(begin(), x)pop_back(): erase(--end())pop_front(): erase(begin())
注意事项
- 遍历list的缓存命中率极差,实际遍历速度比vector慢一个数量级。
- list每个节点额外存了两个指针,16字节,不一定比vector利用率更高。
- list比vector的优势在于可以快速进行头插入和头删除,其他场景都建议使用vector。
三、双端队列 deque
队列的所有操作都发生在队列的两端。双端队列(double ended queue)在队列两端都可以进行插入和删除操作,比起FIFO的单向队列更加灵活。
deque定义和实现
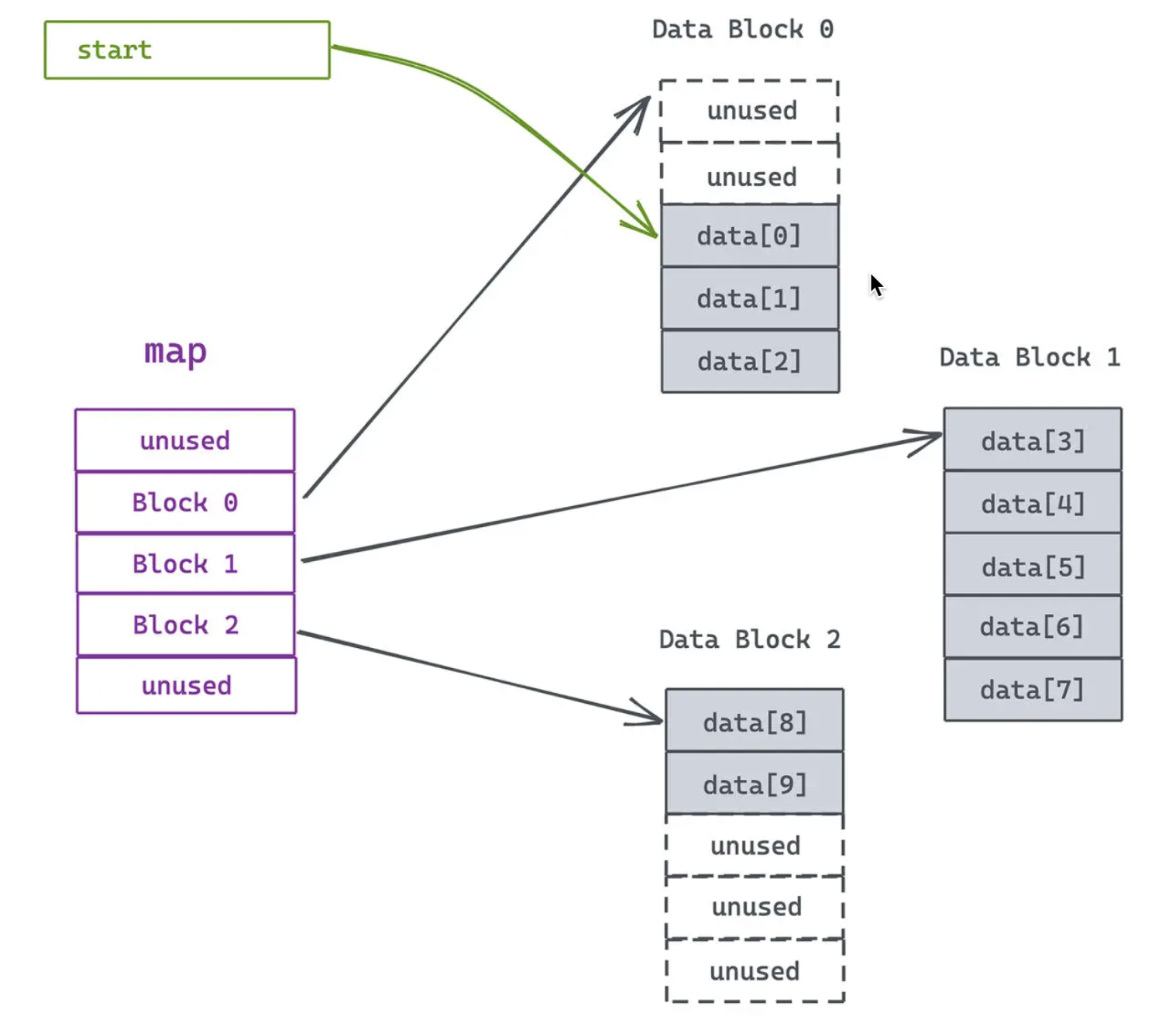
deque使用了分级的思想,使用map管理多段连续内存(分段连续空间):
1
2
3
4
5
6
7
8
9
10
| template <class _Tp, class _Alloc>
class _Deque_base {
...
protected:
_Tp** _M_map;
size_t _M_map_size;
iterator _M_start;
iterator _M_finish;
...
}
|
deque的迭代器屏蔽了底层分块连续的细节,对外可以认为deque的内存空间是连续的。可以直接队deque的元素进行随机访问,时间复杂度是O(1)。
以push_back为例,看push操作的实现:
- 如果当前node下面还有空间,直接使用下面的空间即可。
- 如果当前node已经占满了,查看map。
- 如果map下面还有没有使用的node,使用这个node。
- 如果map下面没有剩余node,查看map使用量。
- 如果map使用率没有过一半,把当前map上已用区间放到中间位置,然后执行3。
- 如果map使用率超过一半,重新申请一个map,然后执行3。
pop操作则是在一个node空闲后,回收这段内存。所以在临界点反复push和pop每次都会触发node内存的申请和释放(对象池复用vector比deque更香)。
思考:为什么不使用vector或list?
- vector在头部插入元素的时间复杂度是O(n),不符合队列两端操作都要高效的需求。如果是大小确定的循环队列,用vector实现就比较合适。
- list不支持随机访问,并且list每push一个元素就需要去申请内存,相比当前的实现一次性可以申请一段连续内存,list方案申请内存的频率更高,性能更差。
deque的随机访问也是O(1),扩容也不需要深拷贝,实现看起来比vector更加全面。但是每次随机访问需要计算map位置和node中偏移,并且缓存命中率更低,实际性能不如vector。“只有在真的需要两端高效” 的场景才用 deque,否则 vector 永远是更快的选择。
思考:node该开多大?
STL的策略:每个node 512字节,或者每个node固定16个元素。
1
2
3
4
| // 每个 node 的元素数:若 sizeof(T) < 512,则为 512/sizeof(T),否则为 1
inline size_t __deque_buf_size(size_t n, size_t sz) {
return n != 0 ? n : (sz < 512 ? size_t(512 / sz) : size_t(1));
}
|
分析:
- node太小:map大,缓存命中率低
- node太大:单node内存浪费严重(和vector的缺点类似)
- 512字节接近一个cpu cache line的大小,是性能拐点。